Negli ultimi anni, i modelli di linguaggio di grandi dimensioni, noti come LLM, sono diventati sempre più protagonisti nel campo dell’interpretazione di documentazione e testi online. Con l’aumento della loro diffusione, è emersa l’esigenza di uno standard chiaro e pratico che possa semplificare l’accesso alle informazioni. Questo è essenziale per ridurre errori, limitare fraintendimenti e migliorare la qualità dei risultati ottenuti.
In questo contesto si inserisce LLMs.txt, un’iniziativa destinata a diventare un punto di riferimento simile a quello di robots.txt utilizzato dai motori di ricerca. Tuttavia, mentre il robots.txt è concepito per i crawler web, l’LLMs.txt è progettato specificamente per i modelli di linguaggio, facilitando un accesso strutturato e coerente ai dati.
L’importanza di LLMs.txt per i modelli di linguaggio
Una delle principali sfide che affrontano gli LLM è l’elaborazione di enormi volumi di dati difficilmente interpretabili. Spesso, i contenuti online sono sovraccarichi di codice JavaScript, complessi menu di navigazione o elementi visivi poco comprensibili. Questo può ostacolare l’efficacia dei modelli nell’estrazione di informazioni significative.
Grazie a un semplice schema in formato Markdown, l’LLMs.txt offre un contesto ordinato, eliminando elementi superflui e mettendo in risalto solo le informazioni cruciali. Non si tratta soltanto di semplificare il compito degli LLM, ma anche di garantire che i materiali analizzati riflettano in modo accurato le intenzioni dell’azienda o dello sviluppatore.
Origini e diffusione dello standard
La proposta dell’LLMs.txt è stata presentata inizialmente da Jeremy Howard ed è rapidamente stata accolta da piattaforme come Mintlify. La sua facilità d’implementazione ha contribuito alla sua diffusione, come dimostrato dal sito llmstxt.directory, dove già numerose organizzazioni stanno adottando questo standard.
Questa crescente adozione evidenzia la formazione di un ecosistema in cui la consultazione dei contenuti da parte delle intelligenze artificiali diventa più fluida e affidabile. Utilizzando strumenti come dotenvx, è possibile generare automaticamente file LLMs.txt partendo da una sitemap XML, facilitando così l’integrazione nei processi esistenti senza necessità di interventi radicali.
Struttura e funzionalità del file LLMs.txt
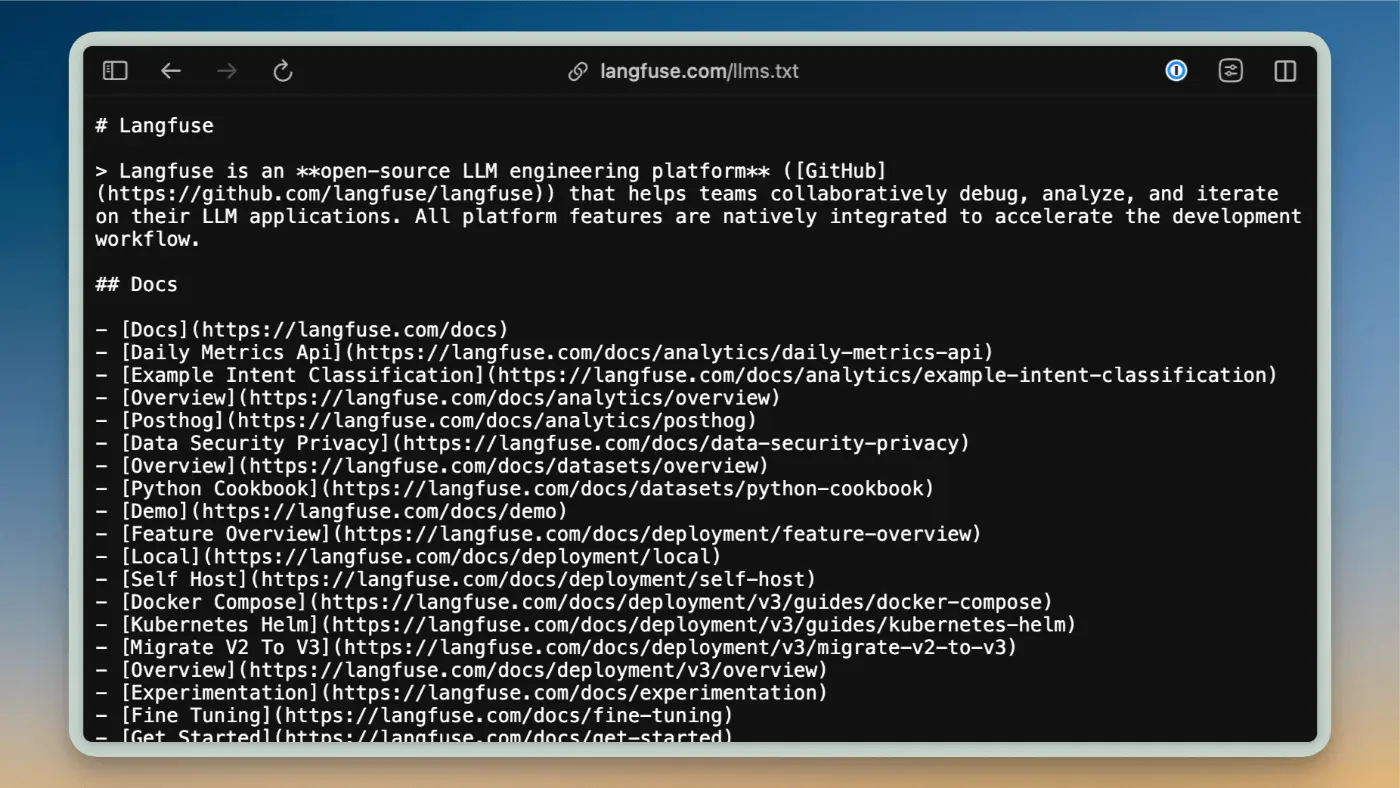
Il file LLMs.txt si compone di un titolo e di un riassunto introduttivo, seguito da sezioni che delineano sia i documenti principali che quelli opzionali. Ogni risorsa viene presentata in modo chiaro, permettendo agli LLM di concentrarsi sui contenuti rilevanti senza doversi confrontare con elementi grafici estranei.
Questo approccio non solo rende il percorso di lettura più razionale, ma consente anche alla macchina di identificare facilmente le informazioni salienti, evitando di perdersi in labirinti di navigazione complessi. Per coloro che necessitano di una visione più articolata, il file llms-full.txt può raccogliere tutta la documentazione in un unico documento Markdown.

I benefici per le aziende e gli sviluppatori
L’introduzione dell’LLMs.txt rappresenta un passo significativo verso una maggiore controllabilità nella diffusione della documentazione. Le aziende che optano per questo standard offrono ai modelli di linguaggio indicazioni mirate, assicurando una interpretazione consistente delle informazioni fondamentali.
Adottare tale strategia può avere un impatto diretto sulla qualità delle risposte fornite dagli LLM, riducendo imprecisioni e fraintendimenti. Ciò consente di creare interazioni più solide e coerenti. Per gli sviluppatori, si tratta di presentare i contenuti in maniera mirata, evitando che informazioni importanti vengano trascurate a causa di formattazioni complesse.
Verso una comunità di pratica e un ecosistema aperto
Tuttavia, non basta semplicemente introdurre lo standard LLMs.txt; il reale successo risiede nella creazione di una comunità di pratica attiva e nel miglioramento degli strumenti necessari per la lettura e l’interpretazione dei contenuti. L’obiettivo finale è quello di promuovere un ecosistema aperto, in grado di adattarsi a contesti applicativi variegati.
Un aspetto interessante è che l’LLMs.txt non è limitato esclusivamente alla documentazione software. Può essere utilizzato per ordinare varie tipologie di informazioni destinate agli LLM, come ad esempio i menu dei ristoranti contenenti raccomandazioni culinarie o curricula vitae per facilitare la valutazione da parte dei sistemi di selezione del personale.
Le esperienze finora raccolte indicano che la direzione intrapresa con l’LLMs.txt è percorribile e vantaggiosa. Anche se non si possono aspettare soluzioni miracolose, l’LLMs.txt fornisce una base solida per ripensare l’interazione uomo-macchina. Suggerisce che l’adozione di uno standard semplice potrebbe influenzare profondamente non solo la fruizione delle informazioni, ma anche la qualità dell’assistenza automatizzata.